I’m not sure how this happened, but I’ve found myself reading old books about old things. History. Philosophy. That sort of thing.
The problem with old books is they keep referencing even older books. Sometimes those books are so old they are out of copyright. Sometimes they are out of print. Finding a quick ebook is usually impossible unless the book is popular enough to show up on Project Gutenberg or Standard Ebooks, my favorite.
Case in point: I’m reading The Enlightenment from the library, on my Kindle. The book is new, but it covers the 18th century, so it necessarily discusses books written in the 18th century. Many of those have 19th-century translations.
One of them is The Adventures of Telemachus. As I understand it, this is a latter-day Greek-ish myth about a traveler guided around Mediterranean civilizations by a god, learning how different styles of governance shape society.
I wanted to take a look at it.
There is no ebook available. I can buy a physical copy printed in 2025 from Amazon for $25, but that seems wrong somehow. There are scans available, including this one from the Internet Archive, published in 1887.
There is even an OCR’d ebook.
Happy day. Let’s take a look:
6 editoe's peeface.
edgment, from this Notice of Yillemain. In our tran*
lation of it we have endeavored to give the sense, but
have not hoped to preserve the pleasing eloquence and
delicate aesthetic finish of the original.
OCR is tricky. Thankfully, the Internet Archive also offers full high-resolution scans.

This got me wondering: in the age of vision-language models (VLMs), how hard would it be to build my own pipeline and produce my own ebook?
Even better, could I do it cheaply by using local VLMs on my own GPU?
ChatGPT, for what it’s worth, recommended against it. The “state of the art” approach would use a mixture of models and traditional OCR techniques. One model looks at a page and segments the structure. OCR models translate those segments. Then software assembles everything.
I dunno man, can you just look at the page and build me an ebook?
Well, almost.
I had two constraints:
- Use a VLM.
- Run it locally, on my RTX 3080 with only 10GB of VRAM.
Quick note: why local? I could build this on top of a state-of-the-art cloud model. I did not want to for two reasons. First, I was curious how much local VLMs have improved since I last played with them. Second, using a cloud model for 500-plus pages would cost enough to make the project feel wrong. If I’m paying almost the price of the Amazon paperback, what are we even doing here? Yes, I am ignoring the hundreds of dollars in labor I am putting into this. Don’t put a price on chasing your dreams.
We worked incrementally, figuring out the pieces together, because I wanted to learn the real shape of the problem.
The first step was evaluating VLMs. What actually runs on my little GPU?
The recommendations ChatGPT had for this problem were already out of date. The best fit I found was gemma3:4b. It runs at about 100 tokens per second on my GPU, supports images, and performed pretty well on the basic image tests Codex built into the harness.
For the next stage, I asked Codex to build a web interface where I could select a scanned page, write and tune a prompt, and see the VLM output.
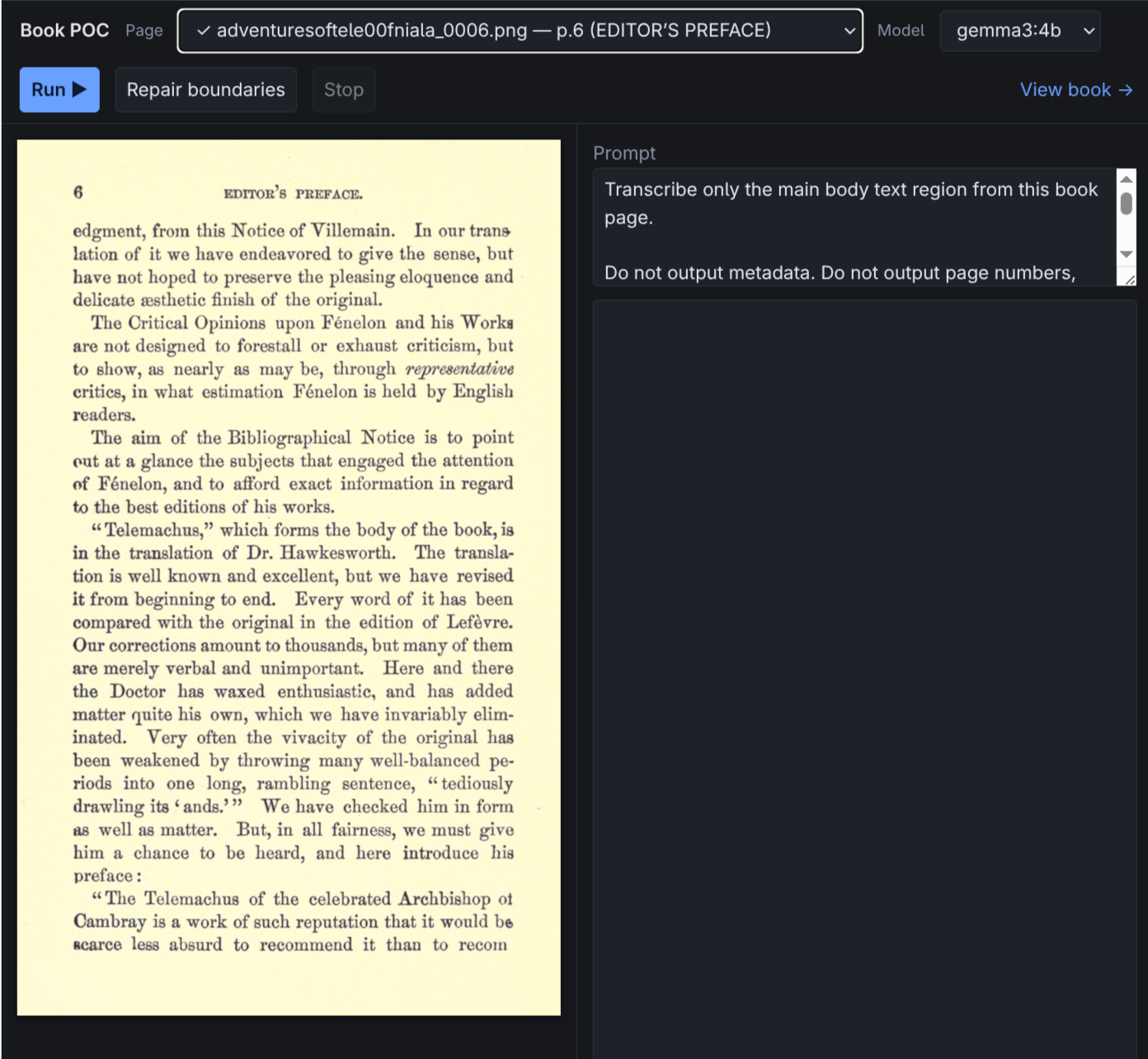
Whatever else happens on this project, this capability is jaw-dropping.
In literal single-digit minutes, I had a web interface for trying the project. It has taken me longer to write this post than it took Codex to build the tool.
My original workflow was simple:
- Feed a page and prompt to the VLM.
- Have the VLM generate structured JSON.
- Use that JSON to mechanically add the page to a growing ebook.
The prompt would include context about the previous page and the current section, chapter, and page number. The VLM could use that context, plus the image, to figure out how to continue the word, paragraph, or section.
Today, the pipeline is more complicated and still does not work.
- First pass: analyze the page structure and identify elements.
- Book pass: combine all page profiles into one big book profile.
- Extraction pass: tune each page prompt based on the profile, then OCR the content.
- Assembly pass: join words and paragraphs mechanically based on the profiles.
I’m not going to cover every twist and turn, but here is a short list of some of the challenges we hit:
- Small language models are unreliable.
That’s it. Nearly every technique worked. None of them worked 100%.
So now I need a solution that is easy and cheap to QA. Ideally by a smarter model.
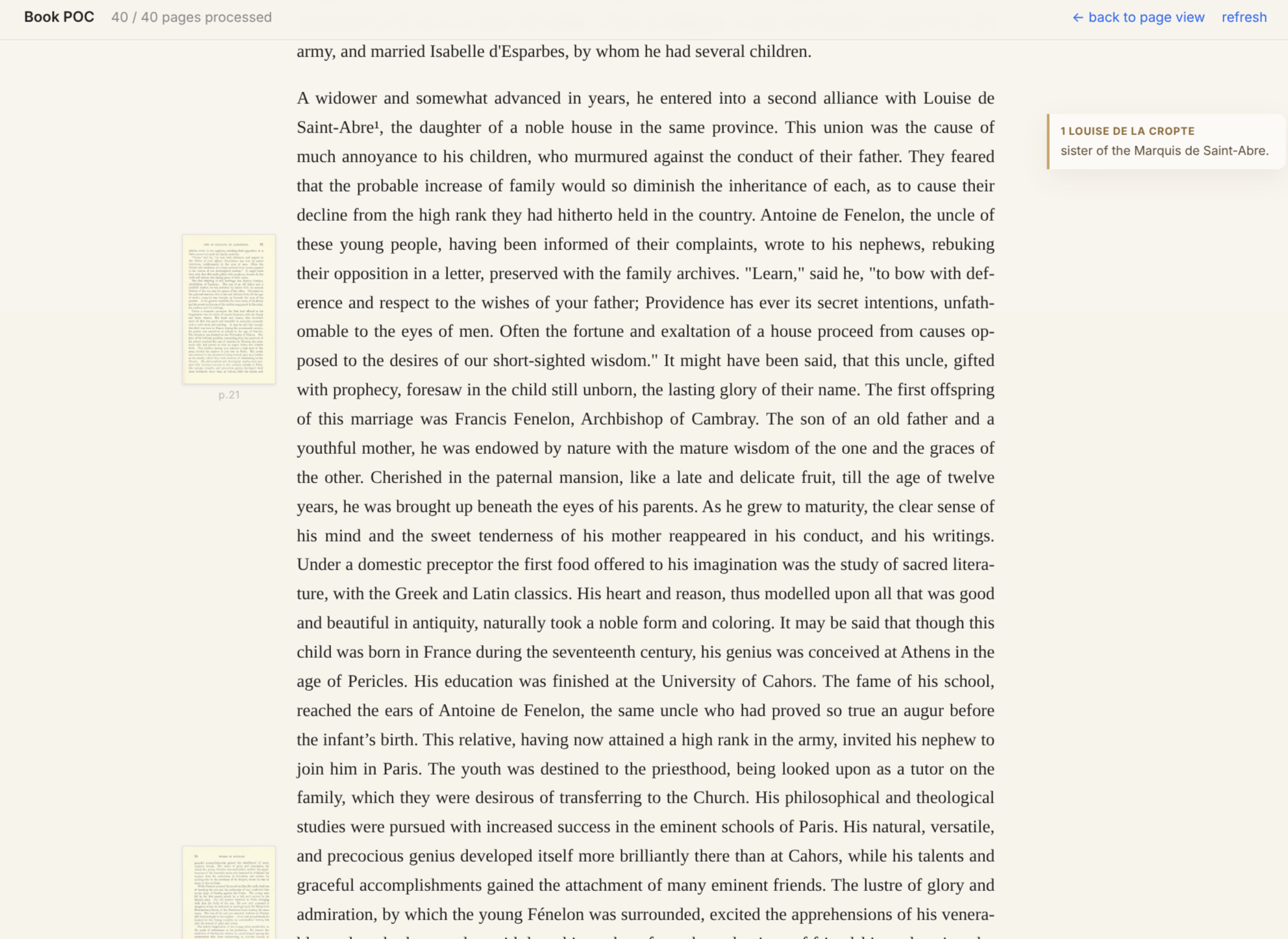
It is tantalizingly close, though. I mean, look at this book: